Data integration involves combining data from multiple sources into a unified view, simplifying analysis and reporting by consolidating disparate datasets. Data fabric, on the other hand, offers a more advanced architecture that uses AI and machine learning to enable seamless data access, management, and governance across diverse environments. While data integration focuses on merging data, data fabric provides an intelligent layer that automates and enhances data connectivity and usability.
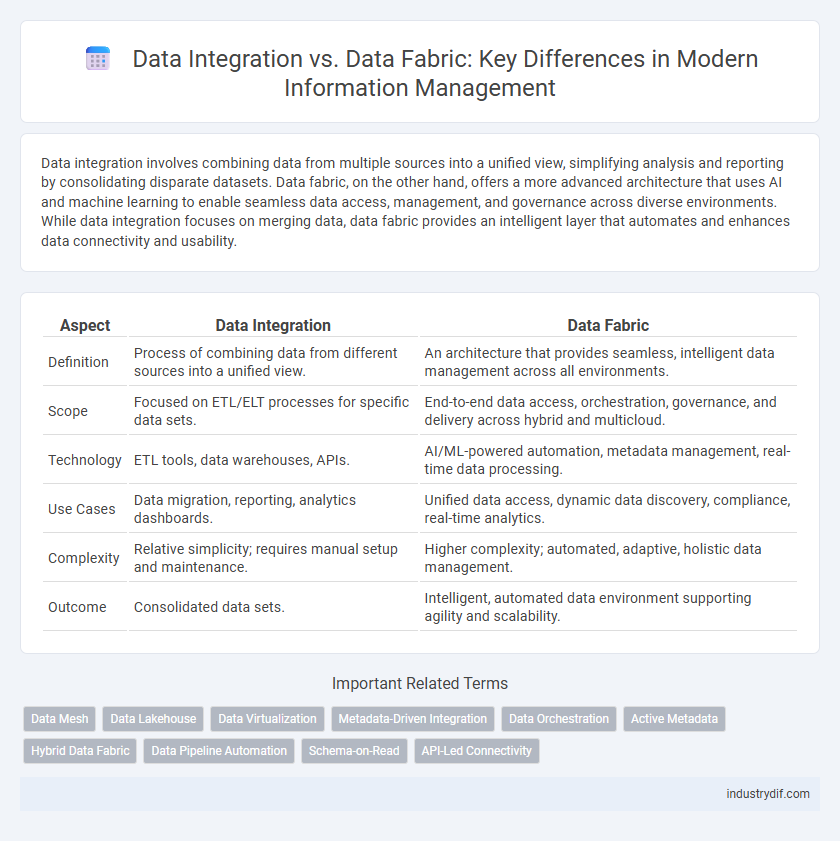
Table of Comparison
| Aspect | Data Integration | Data Fabric |
|---|---|---|
| Definition | Process of combining data from different sources into a unified view. | An architecture that provides seamless, intelligent data management across all environments. |
| Scope | Focused on ETL/ELT processes for specific data sets. | End-to-end data access, orchestration, governance, and delivery across hybrid and multicloud. |
| Technology | ETL tools, data warehouses, APIs. | AI/ML-powered automation, metadata management, real-time data processing. |
| Use Cases | Data migration, reporting, analytics dashboards. | Unified data access, dynamic data discovery, compliance, real-time analytics. |
| Complexity | Relative simplicity; requires manual setup and maintenance. | Higher complexity; automated, adaptive, holistic data management. |
| Outcome | Consolidated data sets. | Intelligent, automated data environment supporting agility and scalability. |
Defining Data Integration: Core Concepts and Applications
Data integration involves consolidating data from diverse sources into a unified view, enabling efficient access and analysis across various systems and platforms. It supports applications such as business intelligence, data warehousing, and master data management by ensuring consistent and accurate data flow. Key techniques include ETL (Extract, Transform, Load), data federation, and real-time data synchronization, which enhance data quality and operational efficiency.
Understanding Data Fabric: Modern Data Architecture Explained
Data Fabric is a modern data architecture that enables seamless data integration across diverse sources, providing a unified and real-time view of information. Unlike traditional data integration methods, Data Fabric employs advanced technologies such as AI, machine learning, and automation to simplify data discovery, governance, and delivery. This approach enhances data accessibility, accelerates decision-making processes, and supports scalable, adaptive analytics environments.
Key Differences Between Data Integration and Data Fabric
Data integration focuses on combining data from multiple sources into a unified view for analysis and reporting, often requiring manual processes and point-to-point connections. Data fabric provides an intelligent, automated architecture that seamlessly manages data across distributed environments, enabling real-time access, governance, and security. Key differences include the scope of automation, scalability, and ability to support complex, hybrid data ecosystems with minimal human intervention.
Core Components of Data Integration Solutions
Core components of data integration solutions include data ingestion, data transformation, and data storage, enabling seamless data flow and consolidation from multiple sources. These components leverage ETL (extract, transform, load) or ELT processes, metadata management, and data quality tools to ensure accurate and consistent data integration across platforms. Effective data integration solutions incorporate APIs, connectors, and workflow automation to facilitate real-time access and unified data views essential for business intelligence and analytics.
Essential Features of Data Fabric Architectures
Data fabric architectures provide a unified data management framework that seamlessly integrates diverse data sources, offering real-time data access and enhanced data governance. Key features include metadata-driven automation, self-service data discovery, and advanced data lineage tracking to ensure transparency and compliance. Data fabrics leverage AI and machine learning to optimize data workflows, enabling scalable, agile, and intelligent data integration across hybrid and multi-cloud environments.
Benefits and Limitations of Data Integration
Data integration enables organizations to consolidate data from multiple sources, improving data consistency and accessibility for better decision-making. It facilitates streamlined workflows and enhanced reporting but can face limitations in scalability and real-time processing due to complex system dependencies. Managing data silos and ensuring data quality remain challenging aspects, requiring continuous monitoring and maintenance.
Advantages and Challenges of Data Fabric
Data Fabric offers a unified architecture that simplifies data integration by providing real-time access and consistency across diverse data sources, enhancing agility and decision-making efficiency. Key advantages include seamless connectivity, automated data governance, and improved data security, enabling organizations to manage complex data environments with reduced operational costs. Challenges involve the complexity of implementation, requiring advanced skills and continuous maintenance to handle evolving data landscapes and ensure scalability.
Real-World Use Cases: Data Integration vs Data Fabric
Data integration streamlines combining data from multiple sources into a unified view, enabling efficient reporting and analytics for businesses such as retail chains consolidating sales data. Data fabric offers a more advanced, AI-driven architecture that provides real-time data access and governance across hybrid cloud and on-premises environments, supporting complex use cases like financial institutions requiring dynamic risk assessment and compliance. Both technologies enhance data-driven decision-making, but data fabric excels in environments requiring continuous data orchestration and intelligent automation.
Choosing Between Data Integration and Data Fabric: Factors to Consider
Choosing between data integration and data fabric depends on factors such as scalability, real-time data access, and complexity of data sources. Data integration suits organizations with simpler, batch-oriented processes, while data fabric supports dynamic environments with diverse and rapidly changing data. Evaluating organizational needs for agility, data governance, and automation helps determine the optimal approach.
Future Trends in Data Management: Integration and Fabric Technologies
Data integration and data fabric technologies are evolving to address increasing data complexity and volume by enabling seamless access and unified views across disparate sources. Future trends emphasize AI-driven automation for metadata management, real-time data processing, and enhanced data governance within integrated environments. Organizations adopting hybrid architectures leverage these advancements to improve agility, scalability, and data-driven decision-making capabilities.
Related Important Terms
Data Mesh
Data Mesh emphasizes decentralized data ownership and domain-oriented architecture, contrasting with traditional Data Integration that relies on centralized ETL processes. Unlike Data Fabric's automated metadata-driven approach, Data Mesh promotes self-serve data infrastructure enabling scalable, domain-specific data product creation.
Data Lakehouse
Data Lakehouse combines the scalability of data lakes with the structured management of data warehouses, enabling unified data integration across diverse sources in real-time. Unlike traditional data integration methods, Data Lakehouse supports seamless data fabric architectures that optimize data governance, accessibility, and analytics efficiency.
Data Virtualization
Data virtualization plays a critical role in data integration by enabling seamless access to disparate data sources without physical consolidation, whereas data fabric extends this concept by providing an intelligent architecture that automates data discovery, governance, and delivery across hybrid environments. By leveraging data virtualization within a data fabric framework, organizations achieve real-time data abstraction and unified data services, optimizing data usability and operational efficiency.
Metadata-Driven Integration
Metadata-driven integration in data fabric leverages comprehensive metadata management to enable seamless connectivity and real-time data processing across diverse sources, enhancing data governance and operational agility. Unlike traditional data integration, data fabric uses metadata to automate data discovery, lineage, and transformation, reducing manual efforts and improving scalability.
Data Orchestration
Data orchestration in data integration involves coordinating data movement and transformation across diverse systems to create unified datasets, while data fabric extends this by embedding intelligent automation and metadata-driven policies for continuous, real-time data management. The data fabric architecture enhances orchestration by enabling seamless data access, governance, and analytics through a holistic, distributed ecosystem that supports dynamic data workflows and scalability.
Active Metadata
Active metadata in data integration enables real-time data mapping and transformation by continuously capturing context and lineage information, enhancing data accuracy and consistency across systems. In contrast, data fabric leverages active metadata to create a unified, intelligent data layer that automates data discovery, governance, and orchestration across hybrid and multi-cloud environments.
Hybrid Data Fabric
Hybrid Data Fabric combines traditional data integration techniques with advanced data fabric architecture to enable seamless access, management, and processing of data across on-premises and cloud environments. This approach optimizes data workflows by unifying disparate data sources, enhancing data governance, and supporting real-time analytics within a hybrid IT infrastructure.
Data Pipeline Automation
Data pipeline automation in data integration involves the scheduled extraction, transformation, and loading (ETL) of data from multiple sources to create unified datasets, enhancing consistency and reducing manual workflows. In contrast, data fabric technology automates data pipeline processes across hybrid and multi-cloud environments by leveraging metadata-driven orchestration, real-time data access, and AI-powered integration to deliver seamless, end-to-end data connectivity.
Schema-on-Read
Schema-on-Read in data integration allows for flexible data querying by applying schema definitions at the time of data access, supporting diverse and unstructured datasets. In contrast, data fabric leverages schema-on-read to unify data from multiple sources dynamically, enhancing real-time analytics and operational agility across hybrid environments.
API-Led Connectivity
API-led connectivity drives data integration by enabling seamless access and orchestration of data across disparate systems, while data fabric expands on this concept by providing a unified architecture that integrates APIs, metadata, and analytics for more intelligent and real-time data management. Leveraging API-led connectivity within a data fabric framework enhances agility, scalability, and governance in complex enterprise environments.
Data Integration vs Data Fabric Infographic