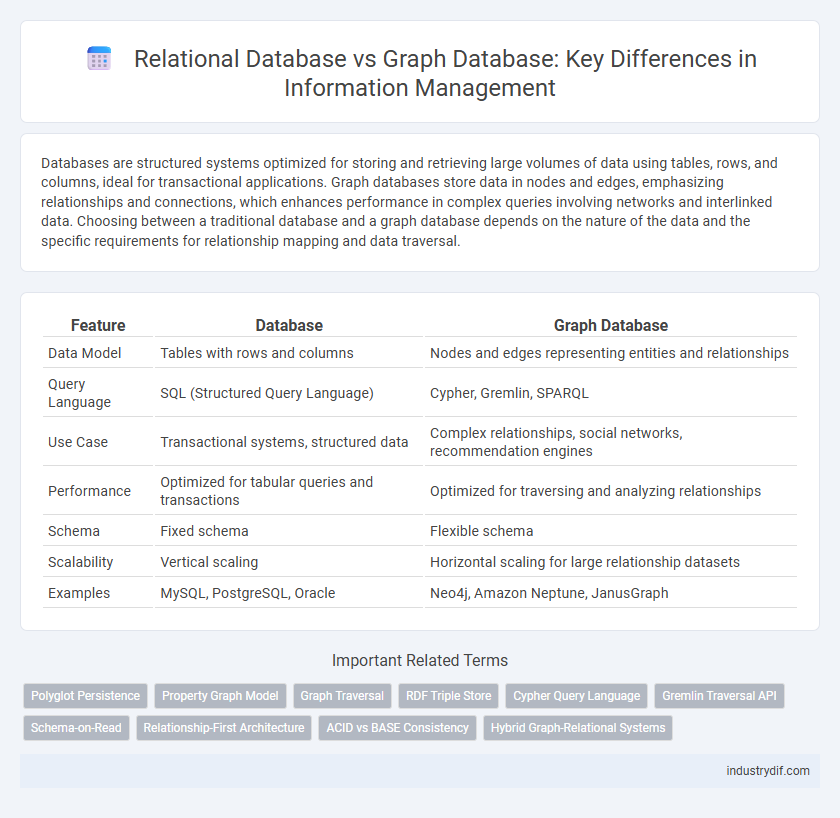
Databases are structured systems optimized for storing and retrieving large volumes of data using tables, rows, and columns, ideal for transactional applications. Graph databases store data in nodes and edges, emphasizing relationships and connections, which enhances performance in complex queries involving networks and interlinked data. Choosing between a traditional database and a graph database depends on the nature of the data and the specific requirements for relationship mapping and data traversal.
Table of Comparison
| Feature | Database | Graph Database |
|---|---|---|
| Data Model | Tables with rows and columns | Nodes and edges representing entities and relationships |
| Query Language | SQL (Structured Query Language) | Cypher, Gremlin, SPARQL |
| Use Case | Transactional systems, structured data | Complex relationships, social networks, recommendation engines |
| Performance | Optimized for tabular queries and transactions | Optimized for traversing and analyzing relationships |
| Schema | Fixed schema | Flexible schema |
| Scalability | Vertical scaling | Horizontal scaling for large relationship datasets |
| Examples | MySQL, PostgreSQL, Oracle | Neo4j, Amazon Neptune, JanusGraph |
Introduction to Traditional Databases vs Graph Databases
Traditional databases, primarily relational databases, organize data into tables with predefined schemas, enabling efficient querying via SQL for structured data. Graph databases utilize nodes, edges, and properties to represent and store complex, interconnected data, optimizing performance for queries involving relationships and networked information. This structural difference makes graph databases highly suitable for use cases like social networks, recommendation systems, and fraud detection, where relationships are central to the data model.
Core Concepts: Relational vs Graph Data Models
Relational databases organize data into tables with rows and columns, using structured query language (SQL) to manage relationships through foreign keys and joins. Graph databases model data as nodes, edges, and properties, enabling direct representation of complex relationships and efficient traversal using graph query languages like Cypher. This core difference allows graph databases to handle interconnected data with high performance, especially in use cases such as social networks, recommendation systems, and fraud detection.
Data Structure and Storage Differences
Relational databases organize data in tables with rows and columns, using structured query language (SQL) for data management, while graph databases store data as nodes, edges, and properties, optimized for representing relationships. Relational models rely on rigid schemas and foreign keys, making them efficient for transactional operations; graph databases use flexible schemas and index-free adjacency, enabling rapid traversal of complex, interconnected data. Storage in relational databases is row- or column-oriented, whereas graph databases employ native graph storage engines designed for efficient graph data processing and retrieval.
Query Languages: SQL vs Graph Query Languages
SQL, the dominant query language for relational databases, excels in handling structured data with predefined schemas and supports powerful operations like joins for querying tabular relationships. Graph query languages such as Cypher, Gremlin, and SPARQL are designed specifically to traverse and analyze complex graph structures, enabling efficient pattern matching and exploring relationships in connected data. While SQL relies on set-based operations, graph query languages leverage graph traversal algorithms to perform deep link analysis, making them ideal for social networks, recommendation systems, and fraud detection.
Performance Considerations and Use Cases
Relational databases excel in structured data storage with efficient ACID-compliant transactions, making them ideal for applications requiring complex queries on tabular data. Graph databases optimize performance for interconnected data by utilizing nodes and relationships, enabling rapid traversal and real-time recommendations in social networks, fraud detection, and knowledge graphs. Choosing between database types depends on data complexity and query patterns, with graph databases sharply outperforming relational models in highly relational use cases.
Scalability and Flexibility
Traditional databases often struggle with scalability when handling complex, interconnected data, whereas graph databases are designed to scale efficiently by naturally modeling relationships as first-class entities. Graph databases offer greater flexibility by enabling dynamic schema evolution and intuitive traversal of relationships, which is essential for applications such as social networks, recommendation systems, and fraud detection. The ability to seamlessly scale across distributed systems while maintaining speedy querying of interconnected data sets makes graph databases superior for handling highly relational and rapidly changing data environments.
Data Relationships and Complexity Handling
Relational databases organize data into tables with predefined schemas, optimizing structured data storage but often struggling with complex, interconnected relationships. Graph databases use nodes, edges, and properties to model and query intricate relationships directly, enabling efficient handling of highly connected data and dynamic schema changes. This flexibility makes graph databases superior for applications involving social networks, recommendation engines, and fraud detection, where relationship complexity and data interconnectivity are critical.
Security Features and Access Control
Database security features typically include role-based access control (RBAC), encryption at rest and in transit, and auditing capabilities to monitor user activities. Graph databases enhance access control through fine-grained permissions at the node and edge levels, enabling more precise data security and lineage tracking. Advanced graph database platforms integrate multi-factor authentication and real-time anomaly detection to protect complex, interconnected data structures.
Industry Adoption and Real-World Examples
Relational databases remain widely adopted across industries such as finance, healthcare, and retail due to their structured schema and robust transaction support, exemplified by Oracle and MySQL usage in banking systems. Graph databases like Neo4j and Amazon Neptune have gained traction in social networks, fraud detection, and recommendation engines by efficiently handling complex relationships and connected data. Companies like Facebook and LinkedIn leverage graph databases for real-time social graph analysis, highlighting industry's shift toward graph-based solutions for dynamic and interconnected datasets.
Choosing the Right Database for Your Application
Selecting the right database depends on the nature of your data and query requirements; traditional relational databases excel in structured data with predefined schemas, supporting complex transactions and SQL queries efficiently. Graph databases are ideal for applications involving interconnected data, such as social networks or recommendation engines, enabling fast traversal and analysis of relationships using graph query languages like Cypher. Evaluating factors like scalability, data model flexibility, and query complexity ensures optimal performance and accurate insights tailored to your application's needs.
Related Important Terms
Polyglot Persistence
Polyglot persistence leverages multiple database types, including traditional relational databases and graph databases, to optimize data storage and retrieval based on specific workload requirements. Graph databases excel in managing highly connected data with complex relationships, enabling efficient queries in social networks, recommendation systems, and fraud detection, while relational databases provide robust transactional support and structured data management.
Property Graph Model
The Property Graph Model in graph databases uses nodes, relationships, and key-value properties to represent complex, interconnected data more naturally than traditional relational databases, enabling efficient traversal and querying of graph structures. Unlike relational databases that rely on tables and foreign keys, graph databases optimize performance for scenarios involving deep relationships and complex networks, making them ideal for social networks, recommendation engines, and fraud detection.
Graph Traversal
Graph traversal techniques excel in navigating complex relationships by efficiently exploring nodes and edges within a graph database, enabling rapid discovery of connections and patterns that traditional relational databases struggle to handle. Utilizing algorithms like depth-first search, breadth-first search, and shortest path, graph traversal enhances query performance in scenarios involving social networks, recommendation systems, and fraud detection.
RDF Triple Store
A database traditionally organizes data in tables with rows and columns, optimizing structured query operations, while a graph database, especially an RDF triple store, represents information as subject-predicate-object triples to model complex relationships and semantic data efficiently. RDF triple stores enable advanced querying using SPARQL, supporting linked data standards and facilitating interoperability across diverse data sources in semantic web applications.
Cypher Query Language
Cypher query language, designed specifically for graph databases like Neo4j, enables intuitive pattern matching and traversal of complex, interconnected data, unlike traditional SQL used in relational databases. This semantic optimization allows efficient querying of relationships and properties, making Cypher essential for applications involving social networks, recommendation systems, and fraud detection.
Gremlin Traversal API
The Gremlin Traversal API offers a powerful and flexible approach for querying graph databases by enabling expressive, declarative path traversal and pattern matching across vertices and edges. Unlike traditional relational databases that use SQL for tabular data queries, Gremlin supports complex graph operations such as vertex filtering, edge traversal, and property retrieval, optimized for highly connected data models.
Schema-on-Read
Schema-on-read in graph databases allows flexible data modeling by applying the schema dynamically during query execution, unlike traditional relational databases where schema-on-write enforces a rigid structure upfront. This approach enhances agility in handling complex, interconnected data and supports evolving data relationships without predefined schemas.
Relationship-First Architecture
Graph databases prioritize relationship-first architecture by storing data as nodes and edges, enabling efficient querying of complex interconnected information. Unlike traditional relational databases that use tables and foreign keys, graph databases excel in managing dynamic relationships, enhancing performance in social networks, recommendation engines, and fraud detection systems.
ACID vs BASE Consistency
Traditional databases typically adhere to ACID (Atomicity, Consistency, Isolation, Durability) principles ensuring strict consistency and reliable transactions, whereas graph databases often prioritize BASE (Basically Available, Soft state, Eventual consistency) to enable high availability and scalability over immediate consistency. This fundamental difference impacts how each system handles data integrity, with relational databases favoring strong consistency and graph databases optimizing for flexible, distributed environments.
Hybrid Graph-Relational Systems
Hybrid graph-relational systems combine the structured query capabilities of relational databases with the flexible, relationship-focused schema of graph databases, enabling complex data connections to be efficiently managed and queried. These systems optimize performance for use cases requiring transactional consistency and dynamic relationship analysis, such as fraud detection and recommendation engines.
Database vs Graph Database Infographic