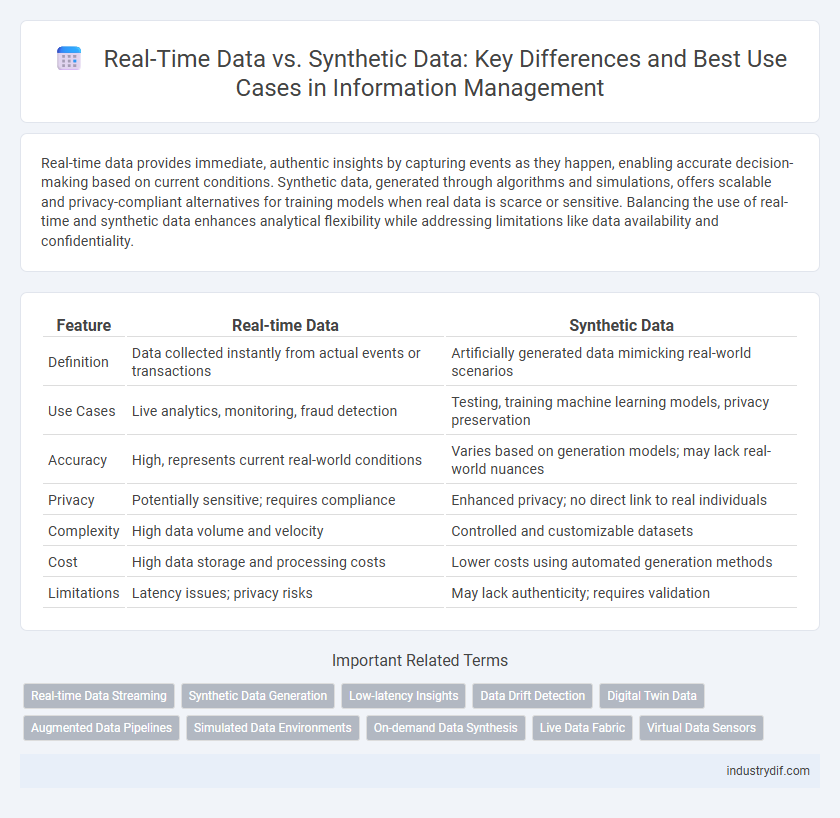
Real-time data provides immediate, authentic insights by capturing events as they happen, enabling accurate decision-making based on current conditions. Synthetic data, generated through algorithms and simulations, offers scalable and privacy-compliant alternatives for training models when real data is scarce or sensitive. Balancing the use of real-time and synthetic data enhances analytical flexibility while addressing limitations like data availability and confidentiality.
Table of Comparison
| Feature | Real-time Data | Synthetic Data |
|---|---|---|
| Definition | Data collected instantly from actual events or transactions | Artificially generated data mimicking real-world scenarios |
| Use Cases | Live analytics, monitoring, fraud detection | Testing, training machine learning models, privacy preservation |
| Accuracy | High, represents current real-world conditions | Varies based on generation models; may lack real-world nuances |
| Privacy | Potentially sensitive; requires compliance | Enhanced privacy; no direct link to real individuals |
| Complexity | High data volume and velocity | Controlled and customizable datasets |
| Cost | High data storage and processing costs | Lower costs using automated generation methods |
| Limitations | Latency issues; privacy risks | May lack authenticity; requires validation |
Understanding Real-Time Data
Real-time data consists of information collected and processed instantly as events occur, enabling immediate analysis and decision-making. It is generated from sources such as IoT devices, sensors, social media feeds, and transaction systems, providing up-to-the-minute accuracy. This immediacy supports applications in areas like financial trading, emergency response, and dynamic resource management where timely insights are critical.
Defining Synthetic Data
Synthetic data is artificially generated information designed to mimic real-world data patterns without exposing sensitive or personal details. It enables safe data sharing and model training by replicating statistical properties of real-time data while ensuring privacy and compliance with regulations. This data type is increasingly crucial for machine learning and analytics when real data access is limited or restricted.
Key Differences Between Real-Time and Synthetic Data
Real-time data is captured directly from live sources, reflecting current conditions with high accuracy and immediacy, while synthetic data is artificially generated to simulate real-world scenarios for testing and training purposes. Real-time data requires continuous collection and processing, providing genuine insights but often facing privacy and availability challenges. Synthetic data offers controlled, scalable datasets with fewer privacy concerns but may lack the nuanced complexity inherent in real-world information.
Advantages of Real-Time Data
Real-time data provides immediate insights by capturing current conditions, enabling faster decision-making and timely responses in dynamic environments. It enhances accuracy and relevance for analytics, as the data reflects up-to-the-minute information rather than relying on historical or simulated datasets. Organizations leveraging real-time data benefit from improved operational efficiency, real-world validation, and the ability to quickly adapt to emerging trends or anomalies.
Benefits of Synthetic Data
Synthetic data enhances data privacy by eliminating the need for sensitive personal information, making it ideal for compliance with regulations like GDPR and HIPAA. It allows for scalable and diverse datasets that improve machine learning model training by covering rare edge cases and scenarios not present in real-world data. Unlike real-time data, synthetic data can be generated quickly and cost-effectively, accelerating development cycles and reducing dependency on unavailable or limited real-world datasets.
Use Cases for Real-Time Data
Real-time data enables instant decision-making in critical applications such as financial trading, autonomous vehicles, and emergency response systems by providing live insights that synthetic data cannot replicate. This type of data supports dynamic monitoring and rapid anomaly detection, enhancing operational efficiency and safety in industries like healthcare and manufacturing. Real-time data's immediacy ensures timely reactions to changing conditions, making it indispensable for use cases requiring up-to-the-minute accuracy and responsiveness.
Applications of Synthetic Data in Industry
Synthetic data finds extensive use in industries such as healthcare, finance, and autonomous driving by enabling machine learning model training without compromising sensitive real-world information. It supports scenarios where real-time data is scarce, expensive, or privacy-restricted, enhancing data diversity and improving algorithm robustness. Companies leverage synthetic data to simulate rare events, conduct stress testing, and accelerate AI development cycles while ensuring compliance with data protection regulations.
Accuracy and Reliability: Real vs Synthetic Data
Real-time data offers high accuracy and reliability by capturing actual events and behaviors as they occur, enabling precise analysis and decision-making. Synthetic data, generated through algorithms and simulations, may lack the nuanced variability of real data but provides controlled, scalable datasets for testing and training models without privacy concerns. While real data ensures authenticity, synthetic data enhances flexibility and accessibility, especially in scenarios where real data is sparse or sensitive.
Security and Privacy Considerations
Real-time data includes live, continuously updated information derived from actual user interactions, which presents inherent risks of data breaches and unauthorized access due to its sensitive and often personal nature. Synthetic data, generated algorithmically to mimic real datasets without containing actual user information, significantly reduces privacy concerns while maintaining data utility for testing and training machine learning models. Employing synthetic data enhances security by minimizing exposure to personally identifiable information (PII), thereby complying more effectively with data protection regulations such as GDPR and HIPAA.
Future Trends in Data Generation
Real-time data generation is expected to advance through enhanced IoT connectivity and edge computing, enabling instantaneous analytics with minimal latency. Synthetic data will increasingly leverage AI and generative models to create highly realistic datasets that maintain privacy while improving machine learning training. The convergence of these technologies will drive hybrid data ecosystems, optimizing accuracy and scalability in future data-driven applications.
Related Important Terms
Real-time Data Streaming
Real-time data streaming enables instantaneous processing and analysis of continuous data flows, crucial for applications like fraud detection, IoT monitoring, and personalized user experiences. This approach leverages technologies such as Apache Kafka and Apache Flink to ensure low latency, high throughput, and scalability in handling dynamic data as it arrives.
Synthetic Data Generation
Synthetic data generation creates artificial datasets that mimic real-world data patterns, enabling machine learning models to train effectively without compromising privacy or requiring extensive data collection. This approach accelerates experimentation and enhances data diversity while mitigating biases and regulatory constraints associated with real-time data.
Low-latency Insights
Real-time data provides low-latency insights by capturing and processing live information instantly, enabling immediate decision-making and rapid response in dynamic environments. Synthetic data, while valuable for augmenting datasets and testing scenarios, typically lacks the immediacy required for real-time analysis and low-latency outcomes.
Data Drift Detection
Real-time data provides immediate, dynamic insights crucial for detecting data drift through continual monitoring of live inputs, while synthetic data offers controlled scenarios to test and validate drift detection algorithms without exposing sensitive information. Effective data drift detection combines the accuracy of real-time data patterns with the scalability and privacy benefits of synthetic datasets to enhance model robustness.
Digital Twin Data
Real-time data provides accurate, up-to-the-moment insights critical for digital twin models by capturing live sensor inputs and operational metrics. Synthetic data complements this by generating scalable, diverse datasets that enhance digital twin simulations without privacy concerns or data scarcity limitations.
Augmented Data Pipelines
Augmented data pipelines integrate real-time data streams with synthetic data generation techniques to enhance model training accuracy and robustness, ensuring continuous updates and diverse scenario coverage. Leveraging these pipelines accelerates data preprocessing, reduces reliance on scarce real-world datasets, and facilitates scalable experimentation for advanced machine learning applications.
Simulated Data Environments
Simulated data environments create synthetic datasets that replicate real-world conditions, enabling extensive testing and analysis without privacy concerns or data collection constraints. These environments facilitate scalable, controlled experiments, enhancing model training and validation by providing diverse, noise-free data tailored to specific scenarios.
On-demand Data Synthesis
On-demand data synthesis allows organizations to generate synthetic data instantly, enabling scalable, privacy-compliant testing and training without the constraints of real-time data availability. This approach enhances flexibility in data-driven applications by providing customized datasets tailored to specific scenarios while avoiding the risks associated with sensitive real-time information.
Live Data Fabric
Live Data Fabric integrates real-time data streams with synthetic data to enhance data accuracy, scalability, and security in dynamic environments. It enables seamless access and processing of live and simulated datasets, optimizing decision-making and predictive analytics across enterprises.
Virtual Data Sensors
Virtual data sensors generate synthetic data by simulating real-time environmental conditions, providing continuous, scalable, and customizable datasets for analytics and machine learning without the limitations of physical sensor deployment. This approach enhances data availability and quality while reducing costs and enabling testing in scenarios where real-time data acquisition is impractical or impossible.
Real-time Data vs Synthetic Data Infographic