Relational databases organize data into tables with predefined schemas, making them ideal for structured data and complex queries using SQL. Graph databases use nodes and edges to represent and store relationships, offering superior performance for connected data and dynamic schema requirements. Choosing between them depends on data complexity, relationship depth, and query patterns specific to the application.
Table of Comparison
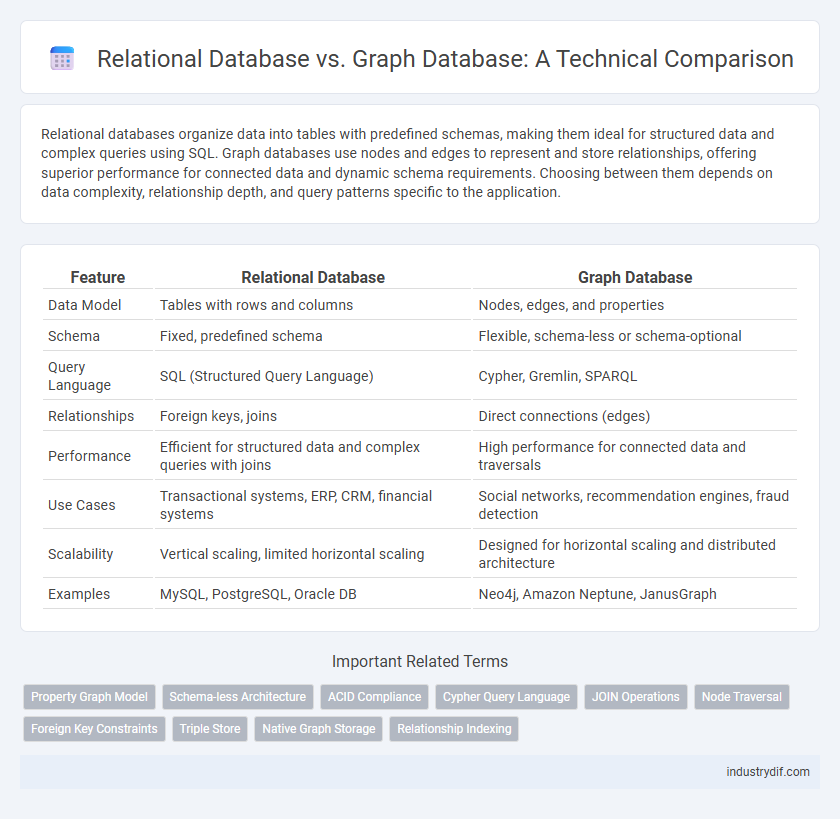
| Feature | Relational Database | Graph Database |
|---|---|---|
| Data Model | Tables with rows and columns | Nodes, edges, and properties |
| Schema | Fixed, predefined schema | Flexible, schema-less or schema-optional |
| Query Language | SQL (Structured Query Language) | Cypher, Gremlin, SPARQL |
| Relationships | Foreign keys, joins | Direct connections (edges) |
| Performance | Efficient for structured data and complex queries with joins | High performance for connected data and traversals |
| Use Cases | Transactional systems, ERP, CRM, financial systems | Social networks, recommendation engines, fraud detection |
| Scalability | Vertical scaling, limited horizontal scaling | Designed for horizontal scaling and distributed architecture |
| Examples | MySQL, PostgreSQL, Oracle DB | Neo4j, Amazon Neptune, JanusGraph |
Overview of Relational and Graph Databases
Relational databases organize data into tables with predefined schemas, using rows and columns to enforce data integrity through relationships established by primary and foreign keys. Graph databases store data as nodes, edges, and properties, enabling efficient representation and traversal of complex, interconnected data structures without rigid schemas. The choice between relational and graph databases hinges on the nature of the data and query patterns, with relational databases excelling in structured, transactional environments and graph databases optimizing for dynamic, relationship-centric queries.
Core Data Models: Tables vs. Nodes and Edges
Relational databases organize data into tables consisting of rows and columns, using primary and foreign keys to establish relationships, which optimizes structured query operations. Graph databases utilize nodes to represent entities and edges to define relationships, enabling complex, dynamic, and multi-dimensional connections with efficient traversal algorithms. This fundamental difference in core data models impacts performance and flexibility in handling interconnected data in use cases like social networks or recommendation engines.
Query Language Comparison: SQL vs. Cypher/Gremlin
SQL, the dominant query language for relational databases, excels at handling structured data with predefined schemas using declarative syntax for complex joins and aggregations. Cypher and Gremlin, designed specifically for graph databases, enable expressive traversal and pattern matching queries that efficiently explore relationships and interconnected data. While SQL optimizes tabular data manipulation, Cypher and Gremlin provide superior performance and intuitiveness for querying complex network structures in social networks, fraud detection, and recommendation systems.
Performance: Join Operations vs. Graph Traversals
Relational databases optimize join operations using indexed tables, enabling efficient data retrieval for structured query patterns but often struggling with complex, multi-level relationships. Graph databases excel in graph traversals by directly linking nodes and edges, resulting in faster performance for queries involving deep joins and interconnected data. This difference makes graph databases particularly advantageous for applications like social networks, fraud detection, and recommendation engines where relationship complexity impacts query efficiency.
Schema Flexibility and Data Modeling
Relational databases enforce rigid schemas requiring predefined tables and fixed columns, making schema evolution complex and time-consuming. In contrast, graph databases offer flexible, schema-less structures that enable dynamic data modeling with nodes and relationships, accommodating evolving and interconnected data effortlessly. This flexibility in graph databases supports agile development and complex queries involving relationships, which are cumbersome in traditional relational models.
Scalability and Distributed Architecture
Relational databases manage structured data using fixed schemas and excel in vertical scaling, but they often face challenges in handling complex, interconnected data at scale. Graph databases leverage distributed architectures that inherently support horizontal scaling by partitioning nodes and edges across multiple servers, enabling efficient querying of relationships in large, dynamic datasets. This distributed model allows graph databases to handle scalability demands in applications like social networks and fraud detection more effectively than traditional relational systems.
Use Cases: Relational vs. Graph Database Applications
Relational databases excel in structured data environments such as financial systems, customer relationship management (CRM), and enterprise resource planning (ERP) where standardized schemas and ACID compliance are critical. Graph databases are ideal for applications involving complex relationships and interconnected data, including social networks, recommendation engines, fraud detection, and network topology analysis. Choosing between relational and graph databases depends on the data model complexity and query patterns, with relational databases favoring tabular data and graph databases optimizing traversal of nodes and edges.
Data Integrity and Consistency Mechanisms
Relational databases enforce data integrity through ACID (Atomicity, Consistency, Isolation, Durability) transactions and schema constraints like primary keys, foreign keys, and unique constraints, ensuring consistent and reliable data states. Graph databases use consistency models tailored for highly connected data, often employing eventual consistency and transactional workflows to maintain data integrity across nodes and relationships. Graph databases optimize traversal performance while relational databases guarantee strict consistency via normalized schemas and structured query execution.
Integration with Existing Systems and Tools
Relational databases excel in integration with existing enterprise systems and tools due to widespread support from SQL-based platforms, robust transactional capabilities, and mature ecosystem compatibility with ETL processes and data warehousing solutions. Graph databases offer seamless integration with modern analytics and machine learning tools through native support for complex relationship queries using graph traversal languages like Cypher or Gremlin, enabling enhanced insights into connected data. Hybrid architectures combining relational and graph databases enable organizations to leverage established infrastructures while optimizing graph-specific workloads without disrupting existing system workflows.
Future Trends in Database Technology
Future trends in database technology show a significant shift towards hybrid models combining relational and graph databases to leverage the strengths of structured query language (SQL) and graph traversal capabilities. Advancements in AI-driven query optimization and distributed architectures are enhancing scalability and real-time analytics for complex data relationships. Emerging standards like Property Graph and RDF integration aim to improve interoperability and semantic querying across diverse data ecosystems.
Related Important Terms
Property Graph Model
The Property Graph Model in graph databases stores data as nodes, relationships, and properties, enabling flexible representation of complex interconnected data unlike the rigid tables and fixed schemas in relational databases. This model supports efficient traversal and querying of deep, multi-dimensional connections through indexed properties, providing superior performance for graph-based queries compared to SQL joins in relational systems.
Schema-less Architecture
Relational databases rely on a fixed schema with predefined tables and columns, making schema changes complex and time-consuming, whereas graph databases utilize a schema-less architecture that allows flexible, dynamic data models ideal for evolving relationships and interconnected data. The schema-less design in graph databases enhances scalability and agility by enabling seamless incorporation of new node and edge types without service disruption or significant restructuring.
ACID Compliance
Relational databases maintain strict ACID compliance, ensuring atomicity, consistency, isolation, and durability through structured query language (SQL) transactions, which guarantees reliable data integrity for complex multi-record operations. Graph databases, while increasingly supporting ACID properties, often prioritize scalability and flexible schema design, making them suitable for dynamic, interconnected data but sometimes compromising full ACID compliance in distributed environments.
Cypher Query Language
Cypher Query Language provides an intuitive pattern-matching syntax specifically designed for querying graph databases like Neo4j, enabling efficient traversal of complex relationships that are cumbersome to model in relational databases. Unlike SQL used in relational databases, Cypher emphasizes nodes and relationships, making it highly effective for semantic queries, graph analytics, and real-time graph processing tasks.
JOIN Operations
Relational databases use JOIN operations to combine rows from two or more tables based on related columns, optimizing structured queries with predefined schemas. Graph databases eliminate complex JOINs by directly storing relationships as edges, enabling faster traversal and querying of interconnected data in dynamic and flexible schemas.
Node Traversal
Relational databases utilize structured tables and join operations for node traversal, which can become computationally expensive with deep, complex relationships. Graph databases employ native graph storage and index-free adjacency, enabling faster, more efficient traversal of nodes and relationships in interconnected data.
Foreign Key Constraints
Relational databases enforce foreign key constraints to maintain referential integrity, ensuring that relationships between tables are consistent and preventing orphaned records. Graph databases, however, represent relationships as first-class entities, eliminating the need for foreign key constraints by directly linking nodes and edges, which optimizes the performance of complex traversals and queries.
Triple Store
Triple stores, a specialized type of graph database, store data as subject-predicate-object triples optimized for semantic querying and reasoning, making them ideal for linked data and knowledge graph applications. Unlike relational databases that use fixed schemas and tables, triple stores offer flexible schema-less data modeling, enabling efficient handling of complex, interconnected data relationships essential for semantic web and AI-driven systems.
Native Graph Storage
Native graph storage enables graph databases to store and process relationships directly within the data model, optimizing performance for complex queries and traversals compared to relational databases that require costly join operations. This intrinsic graph structure allows native graph databases to efficiently handle interconnected data, making them ideal for applications such as social networks, recommendation engines, and fraud detection systems.
Relationship Indexing
Relational databases utilize structured schemas and foreign keys to index relationships, enabling efficient JOIN operations across tables with fixed relationships. Graph databases index relationships as first-class entities using edge pointers, allowing rapid traversal of complex, dynamic relationships and real-time querying of interconnected data.
Relational Database vs Graph Database Infographic