Data consists of real-world information collected from actual events or observations, providing authentic insights for analysis and decision-making. Synthetic data is artificially generated to mimic real data's statistical properties, offering an alternative when privacy, scarcity, or cost issues limit access to genuine datasets. While real data captures true variability, synthetic data enhances scalability and versatility in testing and training machine learning models without compromising sensitive information.
Table of Comparison
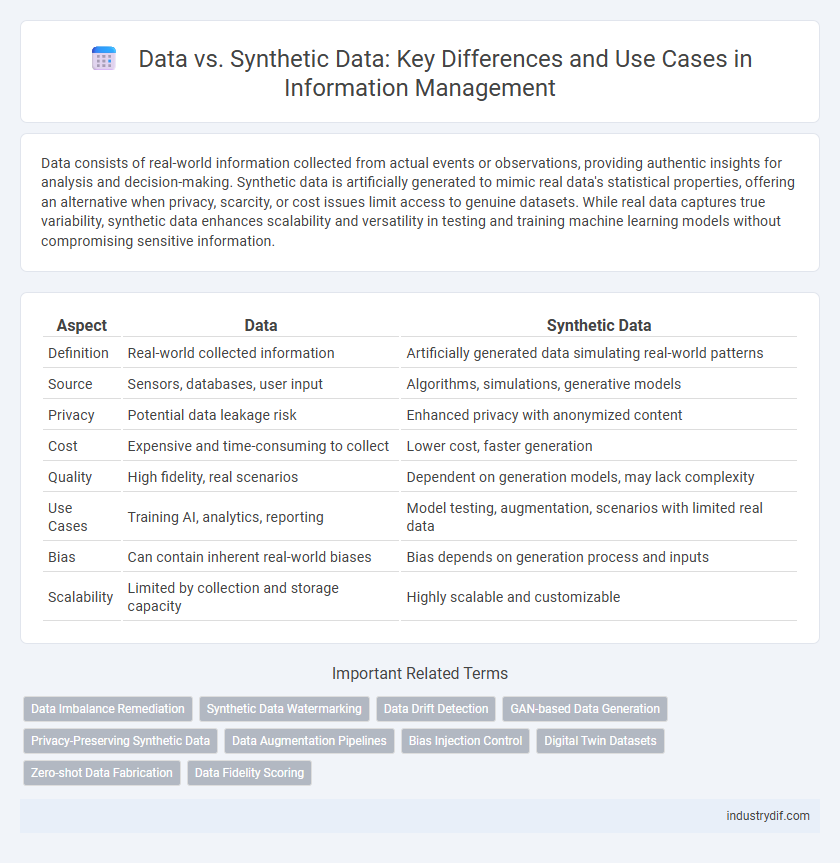
| Aspect | Data | Synthetic Data |
|---|---|---|
| Definition | Real-world collected information | Artificially generated data simulating real-world patterns |
| Source | Sensors, databases, user input | Algorithms, simulations, generative models |
| Privacy | Potential data leakage risk | Enhanced privacy with anonymized content |
| Cost | Expensive and time-consuming to collect | Lower cost, faster generation |
| Quality | High fidelity, real scenarios | Dependent on generation models, may lack complexity |
| Use Cases | Training AI, analytics, reporting | Model testing, augmentation, scenarios with limited real data |
| Bias | Can contain inherent real-world biases | Bias depends on generation process and inputs |
| Scalability | Limited by collection and storage capacity | Highly scalable and customizable |
Understanding Real Data in Industry
Real data in industry consists of authentic information collected from actual events, customer interactions, or operational processes, providing accurate insights into market behavior and system performance. This data is crucial for validating models, improving decision-making, and ensuring reliability in predictive analytics. However, challenges such as privacy concerns, data quality issues, and scarcity in specific scenarios often limit its accessibility and usability.
Defining Synthetic Data and Its Types
Synthetic data is artificially generated information that mimics real-world datasets, created using algorithms and statistical models to preserve the underlying patterns and structures. Types of synthetic data include fully synthetic data, where entire datasets are generated without using any original data points, and partially synthetic data, which replaces sensitive elements within real datasets to protect privacy. Another variant is hybrid synthetic data, combining real and synthetic data to enhance data utility while maintaining confidentiality in machine learning and data analysis.
Key Differences Between Data and Synthetic Data
Data refers to real-world information collected from actual events, users, or sensors, offering authenticity and accuracy for analysis. Synthetic data is artificially generated using algorithms or models to mimic real data patterns while preserving privacy and enabling scalable experimentation. Key differences include origin--real versus generated data--privacy implications, with synthetic data reducing risks, and usage scenarios where synthetic data supports testing without compromising sensitive information.
Common Industry Applications of Synthetic Data
Synthetic data is widely used in industries such as healthcare for training AI models without compromising patient privacy. In finance, it enables fraud detection systems to simulate rare fraudulent transactions for enhanced algorithm accuracy. Autonomous vehicle development leverages synthetic datasets to create diverse driving scenarios that improve machine learning model robustness.
Advantages of Using Synthetic Data
Synthetic data offers significant advantages over real data, including enhanced privacy protection by eliminating personally identifiable information and reducing the risk of data breaches. It enables extensive scalability and diversity for training machine learning models, improving algorithm robustness without the constraints of limited or biased real data. Synthetic data also accelerates development cycles by providing readily available, customizable datasets that simulate complex scenarios difficult to capture in real-world data collection.
Limitations and Challenges of Synthetic Data
Synthetic data faces limitations in accurately replicating complex real-world variations, which can lead to reduced model performance when applied to actual datasets. Challenges include ensuring data privacy without losing essential patterns and addressing potential biases introduced during generation. Furthermore, high-quality synthetic data creation demands extensive computational resources and sophisticated algorithms, impacting scalability and accessibility.
Data Privacy and Security Considerations
Data privacy and security considerations are critical when comparing real data to synthetic data, as synthetic data offers enhanced protection by minimizing exposure of sensitive information. Unlike real data, synthetic datasets reduce risks of re-identification and unauthorized access since they contain artificial, non-identifiable records. Employing synthetic data mitigates compliance challenges with regulations like GDPR and HIPAA while maintaining the integrity of analytical models.
Quality Assurance for Synthetic Data
Synthetic data enables robust quality assurance processes by replicating real-world data patterns without exposing sensitive information. Advanced validation techniques, including statistical tests and machine learning models, ensure synthetic data maintains high fidelity and utility for testing and training purposes. Continuous evaluation against benchmarks guarantees that synthetic datasets effectively support accurate, reliable insights in AI and analytics applications.
Use Cases: Real Data vs Synthetic Data
Real data is essential for training machine learning models in applications requiring high accuracy, such as medical diagnosis and autonomous driving, where authentic patterns and variations are critical for reliability. Synthetic data proves valuable in scenarios with data scarcity, privacy concerns, or the need for large-scale data augmentation, including fraud detection, facial recognition, and testing software systems. Enterprises leverage synthetic data to simulate rare events and enhance model robustness without compromising sensitive information, complementing the insights gained from real-world datasets.
Future Trends in Data Generation and Usage
Future trends in data generation emphasize the growing integration of synthetic data to supplement real datasets, enhancing privacy and reducing collection costs. Advances in AI-driven generative models improve the quality and realism of synthetic data, making it a crucial resource for training machine learning algorithms across industries. The convergence of synthetic and real data accelerates innovation in sectors like healthcare, autonomous driving, and finance, driving more robust, scalable, and ethical AI applications.
Related Important Terms
Data Imbalance Remediation
Data imbalance remediation involves techniques such as oversampling, undersampling, and synthetic data generation to address skewed class distributions in datasets. Synthetic data, generated through methods like GANs or SMOTE, enhances model performance by creating balanced, diverse training samples without compromising data privacy.
Synthetic Data Watermarking
Synthetic data watermarking embeds imperceptible markers within artificial datasets to ensure traceability and ownership verification while maintaining data utility for machine learning applications. This technique enhances security and intellectual property protection by enabling detection of unauthorized data usage and preventing model theft in AI development.
Data Drift Detection
Data drift detection relies on monitoring real data changes over time to identify shifts in distribution, whereas synthetic data often lacks the natural variability essential for accurate drift analysis. Effective data drift detection requires real-world data characteristics to ensure models remain robust and reliable in dynamic environments.
GAN-based Data Generation
GAN-based data generation leverages Generative Adversarial Networks to create high-quality synthetic datasets that closely mimic real-world data distributions, enhancing privacy preservation and reducing the need for costly data collection. This approach improves machine learning model training by providing diverse, labeled synthetic data while mitigating biases inherent in original datasets.
Privacy-Preserving Synthetic Data
Privacy-preserving synthetic data generates artificial datasets that closely mimic real-world data while eliminating personally identifiable information, reducing the risk of privacy breaches. Techniques such as differential privacy and generative adversarial networks (GANs) enable organizations to share and analyze data securely, supporting compliance with regulations like GDPR and HIPAA.
Data Augmentation Pipelines
Data augmentation pipelines enhance model robustness by integrating synthetic data, which simulates diverse scenarios beyond real data limitations. Leveraging techniques like GANs and simulations, these pipelines expand datasets efficiently, improving accuracy in machine learning tasks.
Bias Injection Control
Data derived from real-world sources often contains inherent biases that can distort analytical outcomes, while synthetic data generation allows for precise bias injection control by adjusting algorithms to simulate or eliminate specific patterns. Implementing synthetic data helps improve model fairness and accuracy through customizable parameters that manage bias levels, ensuring more reliable decision-making processes.
Digital Twin Datasets
Digital twin datasets leverage synthetic data to simulate real-world conditions, enabling enhanced accuracy and scalability in modeling complex systems. Unlike traditional data, synthetic data in digital twins provides controlled variability and improves data privacy while supporting predictive analytics and scenario testing.
Zero-shot Data Fabrication
Zero-shot data fabrication leverages synthetic data generation techniques to create high-quality datasets without requiring prior examples or labeled data, addressing the limitations of sparse or unavailable real-world data. This approach enhances machine learning performance by simulating diverse data scenarios, enabling models to generalize effectively in zero-shot learning environments.
Data Fidelity Scoring
Data fidelity scoring quantitatively assesses the accuracy and representativeness of synthetic data compared to real datasets by measuring statistical similarity, feature distribution alignment, and preservation of underlying correlations. High fidelity scores ensure synthetic data effectively mimics real data characteristics, enabling reliable model training and validation without compromising privacy.
Data vs Synthetic Data Infographic