Big Data involves processing vast volumes of diverse and complex datasets to uncover patterns and insights at scale, fueling advanced analytics and machine learning applications. Tiny Data refers to small, precise datasets that provide high-quality, actionable insights quickly, often enhancing decision-making in real-time scenarios. Understanding the differences between Big Data and Tiny Data enables organizations to choose the appropriate data strategy for specific business challenges and optimize resource allocation.
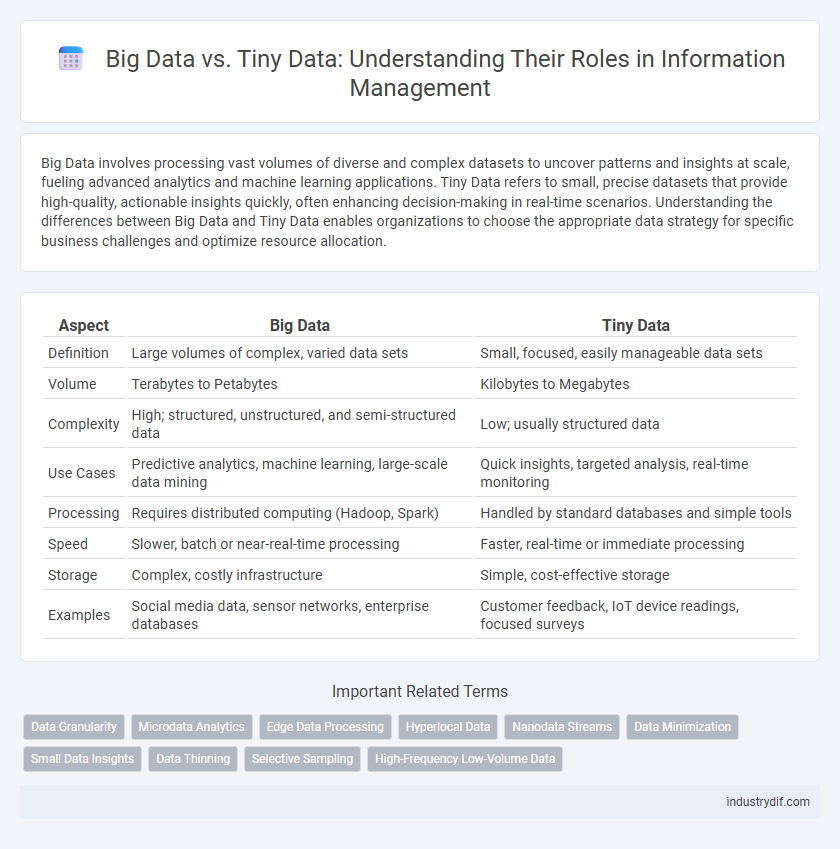
Table of Comparison
| Aspect | Big Data | Tiny Data |
|---|---|---|
| Definition | Large volumes of complex, varied data sets | Small, focused, easily manageable data sets |
| Volume | Terabytes to Petabytes | Kilobytes to Megabytes |
| Complexity | High; structured, unstructured, and semi-structured data | Low; usually structured data |
| Use Cases | Predictive analytics, machine learning, large-scale data mining | Quick insights, targeted analysis, real-time monitoring |
| Processing | Requires distributed computing (Hadoop, Spark) | Handled by standard databases and simple tools |
| Speed | Slower, batch or near-real-time processing | Faster, real-time or immediate processing |
| Storage | Complex, costly infrastructure | Simple, cost-effective storage |
| Examples | Social media data, sensor networks, enterprise databases | Customer feedback, IoT device readings, focused surveys |
Understanding Big Data and Tiny Data
Big Data refers to extremely large datasets characterized by high volume, velocity, and variety, enabling advanced analytics and real-time decision-making across industries. Tiny Data, in contrast, involves small, manageable data sets that provide precise, actionable insights often used for targeted, specific problems or granular analysis. Understanding the differences between Big Data and Tiny Data helps organizations optimize data strategies for scalability, accuracy, and relevant application in business intelligence.
Key Differences Between Big Data and Tiny Data
Big Data refers to extremely large datasets characterized by high volume, velocity, and variety, requiring advanced analytics and storage technologies to extract meaningful insights. Tiny Data, in contrast, involves small, precise data points that are easily manageable and often used for immediate, specific decision-making tasks. Key differences include data scale, complexity, processing methods, and usage scope, with Big Data supporting broad, predictive analytics and Tiny Data enabling focused, real-time analysis.
Use Cases for Big Data in Industry
Big Data in industry powers advanced analytics for optimizing supply chain management, enhancing customer personalization, and predictive maintenance of machinery to reduce downtime. Industries like manufacturing, retail, and finance leverage Big Data to analyze vast datasets from IoT devices, transaction records, and social media to drive data-driven decisions and improve operational efficiency. Real-time processing of complex, high-volume data streams enables companies to innovate, forecast trends, and maintain competitive advantage.
Tiny Data Applications and Real-World Examples
Tiny Data applications excel in delivering precise, actionable insights by analyzing small, focused datasets tailored to specific problems. Real-world examples include personalized healthcare monitoring, where wearable devices track individual biometrics for customized treatment plans, and smart home systems that optimize energy use based on daily user habits. These applications leverage minimal yet highly relevant data, ensuring swift processing and enhanced privacy compared to Big Data approaches.
Data Volume: Scale and Impact
Big Data involves processing massive volumes of information, often measured in terabytes or petabytes, enabling comprehensive analysis across diverse sources to uncover complex patterns and insights. Tiny Data, in contrast, deals with small, focused datasets typically under megabytes, emphasizing precision and relevance for immediate decision-making. The scale difference impacts storage requirements, computational power, and potential applications, with Big Data driving large-scale predictive analytics and Tiny Data supporting agile, context-specific tasks.
Speed and Processing Requirements
Big Data demands extensive computational power and storage capacity to process vast, complex datasets, often requiring distributed systems and parallel processing techniques. In contrast, Tiny Data prioritizes rapid processing with minimal resource usage, ideal for real-time decision-making and edge computing environments. Speed in Tiny Data applications is crucial, enabling instantaneous insights without the latency associated with Big Data's heavier processing requirements.
Storage, Security, and Privacy Considerations
Big Data requires vast storage infrastructures, often leveraging distributed cloud systems to efficiently manage petabytes of information, whereas Tiny Data typically fits within localized, minimal storage environments. Security measures for Big Data emphasize robust encryption, continuous monitoring, and advanced threat detection to protect expansive datasets from breaches, while Tiny Data security focuses on simpler, direct controls due to its limited volume and sensitivity. Privacy considerations in Big Data involve complex regulations like GDPR and CCPA to handle aggregated user information responsibly, contrasting with Tiny Data's emphasis on strict consent and minimal data collection to reduce privacy risks.
Analytical Approaches: Big Data vs Tiny Data
Big Data analytics relies on large-scale datasets processed through distributed computing frameworks like Hadoop and Spark to uncover complex patterns and trends. Tiny Data analytics focuses on small, specific datasets analyzed using traditional statistical methods or simple machine learning models for quick, actionable insights. While Big Data emphasizes volume and velocity, Tiny Data prioritizes data quality and context for targeted decision-making.
Choosing the Right Data Strategy
Big Data involves massive datasets requiring advanced analytics and storage solutions, while Tiny Data focuses on small, highly relevant datasets that deliver precise insights quickly. Choosing the right data strategy depends on business objectives, processing capabilities, and data complexity, balancing scale with actionable detail. Optimizing data utilization enhances decision-making efficiency and competitive advantage.
Future Trends in Data Management
Advancements in artificial intelligence and machine learning are driving the integration of Big Data and Tiny Data, enabling more precise and context-aware insights for future data management. Edge computing is becoming crucial for processing Tiny Data locally, reducing latency and enhancing real-time analytics. The convergence of these data types supports scalable, efficient, and secure data ecosystems essential for next-generation applications and decision-making processes.
Related Important Terms
Data Granularity
Big Data involves vast volumes of information with coarse granularity, enabling broad trend analysis and pattern recognition across diverse datasets. Tiny Data features highly granular, detailed data points typically used for precise, context-specific insights and real-time decision-making.
Microdata Analytics
Microdata analytics leverages granular, high-resolution datasets often categorized under tiny data to deliver precise insights and real-time decision-making capabilities. Unlike big data, which emphasizes volume and variety, microdata analytics prioritizes depth and contextual relevance to enhance personalized user experiences and operational efficiency.
Edge Data Processing
Edge data processing enhances Big Data analytics by analyzing information closer to data sources, reducing latency and bandwidth usage compared to centralized Big Data frameworks. Tiny Data involves localized datasets processed at the edge, enabling real-time decision-making and efficient resource utilization in IoT and edge computing environments.
Hyperlocal Data
Hyperlocal data emphasizes highly specific, geographically localized datasets, contrasting with big data's vast and varied information sources. Leveraging hyperlocal data enables businesses to deliver personalized experiences and actionable insights tailored to neighborhood-level consumer behavior.
Nanodata Streams
Nanodata streams represent the smallest units of data continuously generated at a microscopic scale, enabling real-time, hyper-granular analysis beyond traditional big data capabilities. These streams offer precise insights by capturing instantaneous changes in environment or device metrics, facilitating advanced applications in IoT, healthcare, and personalized technology.
Data Minimization
Big Data involves processing vast volumes of diverse data sets to uncover patterns and insights, while Tiny Data emphasizes collecting minimal, relevant information to reduce storage costs and privacy risks. Data minimization in Tiny Data strategies enhances compliance with data protection regulations by limiting data collection to what is strictly necessary for specific analytics.
Small Data Insights
Small Data Insights emphasize the analysis of limited, specific datasets to generate actionable information that drives precise decision-making. Unlike Big Data, Small Data prioritizes quality over quantity, enabling deeper understanding through targeted, context-rich analytics.
Data Thinning
Data thinning reduces big data volume by selectively extracting relevant tiny data subsets to improve processing speed and analysis efficiency. This technique balances maintaining critical information while minimizing storage and computational costs inherent in big data environments.
Selective Sampling
Selective sampling in big data involves strategically extracting smaller, relevant datasets from massive volumes to enhance analytical efficiency and accuracy, contrasting with tiny data which inherently consists of compact, manageable datasets designed for targeted insights. This approach optimizes resource allocation by focusing computational power on high-value data points, improving decision-making and predictive modeling in complex environments.
High-Frequency Low-Volume Data
High-frequency low-volume data refers to datasets generated continuously at rapid intervals but with relatively small size per instance, enabling real-time analytics and timely decision-making. This contrasts with big data's large-scale, high-volume datasets that require extensive storage and processing resources for long-term pattern extraction and strategic insights.
Big Data vs Tiny Data Infographic