Big Data centralizes vast amounts of information for analysis, enabling comprehensive insights but raising concerns about data privacy and security. Federated Learning processes data locally on devices, allowing models to improve collaboratively without sharing raw data, thereby enhancing privacy preservation. This decentralized approach contrasts with traditional Big Data methods by minimizing risks associated with data breaches while maintaining analytical power.
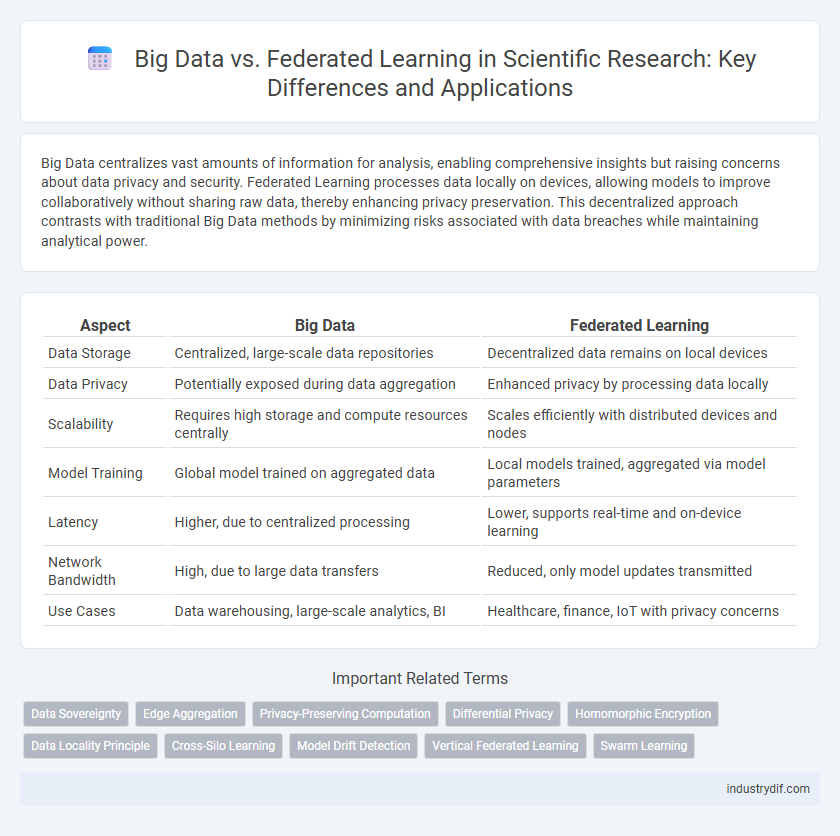
Table of Comparison
| Aspect | Big Data | Federated Learning |
|---|---|---|
| Data Storage | Centralized, large-scale data repositories | Decentralized data remains on local devices |
| Data Privacy | Potentially exposed during data aggregation | Enhanced privacy by processing data locally |
| Scalability | Requires high storage and compute resources centrally | Scales efficiently with distributed devices and nodes |
| Model Training | Global model trained on aggregated data | Local models trained, aggregated via model parameters |
| Latency | Higher, due to centralized processing | Lower, supports real-time and on-device learning |
| Network Bandwidth | High, due to large data transfers | Reduced, only model updates transmitted |
| Use Cases | Data warehousing, large-scale analytics, BI | Healthcare, finance, IoT with privacy concerns |
Introduction to Big Data and Federated Learning
Big Data involves the large-scale collection, storage, and analysis of vast and diverse datasets to uncover patterns, trends, and insights critical for scientific research and decision-making. Federated Learning is a decentralized machine learning approach that enables multiple devices or institutions to collaboratively train models locally on data without the need to share raw data, thus preserving privacy and compliance with data protection regulations. Both methodologies address significant challenges in handling voluminous data, with Big Data emphasizing centralized processing and Federated Learning focusing on distributed model training.
Core Concepts: Definitions and Differences
Big Data refers to the extensive datasets characterized by high volume, velocity, and variety, enabling comprehensive analysis through centralized aggregation and processing. Federated Learning is a decentralized machine learning approach where multiple devices collaboratively train a model locally without sharing raw data, enhancing privacy and security. The core difference lies in data handling: Big Data relies on centralized data consolidation, whereas Federated Learning preserves data locality by transmitting only model updates.
Data Privacy and Security Considerations
Big Data analytics often involves centralized data storage that increases risks of data breaches and unauthorized access, raising significant privacy concerns. Federated Learning mitigates these issues by enabling decentralized model training directly on local devices, ensuring that sensitive data remains on-premise while only model updates are shared. This approach significantly enhances data security and privacy compliance by minimizing data exposure and reducing attack surfaces.
Scalability in Big Data vs Federated Learning
Big Data systems achieve scalability by leveraging distributed storage and parallel processing frameworks such as Hadoop and Spark, enabling the handling of massive datasets across numerous nodes. Federated Learning scales by decentralizing model training to edge devices or localized servers, reducing the need for central data aggregation and minimizing communication overhead among participants. While Big Data emphasizes centralized data collection and processing, Federated Learning prioritizes scalability through privacy-preserving, distributed computation across heterogeneous and often resource-constrained devices.
Data Ownership and Governance
Big Data centralizes vast datasets, often raising concerns about data ownership due to third-party storage and processing, which complicates governance and compliance with privacy regulations such as GDPR. Federated Learning enables decentralized model training across multiple devices or servers, allowing data to remain local and under the direct control of owners, enhancing data sovereignty and reducing the risk of unauthorized access. This distributed approach supports stricter governance frameworks by ensuring data privacy while enabling collaborative analytics without transferring raw data.
Model Training Approaches
Big Data model training relies on centralized data aggregation, enabling high computational power but raising privacy concerns due to extensive data sharing. Federated Learning distributes the training process across multiple devices or nodes, allowing models to learn from decentralized data while preserving user privacy. This approach significantly reduces the risk of data breaches and complies better with data protection regulations.
Communication and Computational Efficiency
Big Data analytics requires extensive data transfer to centralized servers, resulting in significant communication overhead and latency, whereas Federated Learning minimizes data movement by processing information locally on edge devices, enhancing communication efficiency. Computationally, Big Data frameworks often rely on powerful centralized infrastructure capable of handling massive datasets, while Federated Learning distributes computation across numerous decentralized nodes, reducing server load but increasing the need for efficient local processing and resource management. This trade-off highlights Federated Learning's advantage in scenarios demanding improved privacy and reduced network bandwidth without compromising computational performance.
Real-World Applications in Science and Industry
Big Data enables large-scale data aggregation and centralized analysis, facilitating breakthroughs in genomics, climate modeling, and predictive maintenance across industries. Federated Learning preserves data privacy by training decentralized AI models on local datasets, proving essential in healthcare for collaborative disease diagnosis without sharing sensitive patient information. Both approaches optimize scientific research and industrial innovation by balancing data accessibility with security and scalability requirements.
Challenges and Limitations
Big Data faces challenges related to privacy concerns, high computational costs, and data storage requirements due to its centralized nature. Federated Learning mitigates data privacy issues by decentralizing model training but encounters limitations in communication overhead, heterogeneous data distribution, and system scalability. Both approaches struggle with ensuring data quality and managing model convergence in complex, real-world applications.
Future Perspectives and Emerging Trends
Future perspectives in big data emphasize enhanced scalability and integration with artificial intelligence to manage exponentially growing datasets efficiently. Federated learning is gaining traction by addressing privacy concerns through decentralized model training, enabling collaborative analytics without data sharing. Emerging trends highlight the convergence of these fields, leveraging edge computing and advanced encryption to create secure, real-time, and large-scale analytical frameworks.
Related Important Terms
Data Sovereignty
Big Data analytics centralizes vast datasets, raising significant concerns about data sovereignty due to cross-border data transfers and jurisdictional challenges. Federated Learning mitigates these issues by enabling decentralized model training on local devices, preserving data ownership and complying with regional privacy regulations.
Edge Aggregation
Edge aggregation in federated learning significantly reduces the communication overhead by locally combining model updates before transmitting to the central server, contrasting with big data approaches that rely on centralized data collection and processing. This localized aggregation enhances privacy preservation and bandwidth efficiency, making federated learning more scalable and suitable for distributed edge environments compared to traditional big data methodologies.
Privacy-Preserving Computation
Big Data analytics involves centralized data aggregation that often raises significant privacy concerns due to sensitive information exposure risks. Federated Learning enables distributed model training across multiple devices or servers, ensuring data remains locally stored, thereby enhancing privacy-preserving computation through secure multi-party computation and differential privacy techniques.
Differential Privacy
Big Data analytics often face challenges in preserving user privacy due to centralized data aggregation, whereas Federated Learning enables model training across distributed devices, minimizing direct data exposure and enhancing Differential Privacy protection. By integrating Differential Privacy mechanisms within Federated Learning frameworks, the approach ensures that individual data points remain indistinguishable, thereby reducing the risk of re-identification compared to traditional Big Data methods.
Homomorphic Encryption
Homomorphic encryption enables secure computation on encrypted data, maintaining privacy in both Big Data analytics and Federated Learning environments by allowing data processing without decryption. This cryptographic method enhances Federated Learning by preventing data leakage during model training, while Big Data benefits from privacy-preserving analytics on distributed datasets.
Data Locality Principle
Big Data analytics centralizes vast datasets to extract patterns and insights, often requiring significant data movement that challenges privacy and bandwidth constraints. Federated Learning adheres to the Data Locality Principle by enabling model training directly on distributed edge devices, minimizing data transfer while preserving data privacy and security.
Cross-Silo Learning
Cross-silo learning in federated learning enables multiple organizations to collaboratively train machine learning models on decentralized data while preserving data privacy, contrasting with traditional big data approaches that aggregate data into a central repository for analysis. This method reduces data transfer risks and regulatory burdens, making it ideal for sensitive environments such as healthcare and finance where data governance and security are paramount.
Model Drift Detection
Model drift detection in Big Data environments relies heavily on continuous monitoring of centralized datasets, enabling robust anomaly identification through extensive historical data comparisons. Federated learning enhances model drift detection by leveraging decentralized data sources to identify local distribution shifts, preserving data privacy while maintaining model adaptability across diverse nodes.
Vertical Federated Learning
Vertical Federated Learning enables collaborative model training across organizations possessing different features of the same individuals, enhancing data privacy by preventing raw data sharing compared to traditional Big Data centralized approaches. This method is particularly effective in sectors like finance and healthcare, where vertical data partitioning is common and data confidentiality is critical.
Swarm Learning
Swarm Learning leverages decentralized data processing by enabling multiple institutions to collaboratively train machine learning models without sharing raw data, addressing privacy and compliance challenges in Big Data environments. Unlike traditional centralized Big Data approaches, Swarm Learning utilizes blockchain-based synchronization and peer-to-peer networks to enhance scalability and secure multi-party collaboration across heterogeneous datasets.
Big Data vs Federated Learning Infographic